包含关键字 shadowsock 的文章
VPS重做系统都需要做什么
重做系统都快成日常了,看来还是需要整理一下。
使用dropbox同步备份网站和数据库
自从用了Shadowsocks,整个人都精神多了!
今天开整Dropbox,话说这货也被Q了。
废话不多说
以下内容需要翻{防屏蔽}墙使用,如果没有,可以参考老高的这篇文章搭建一个稳定又极速的翻{防屏蔽}墙环境
下载
在官网找到linux专用脚本,执行一下对应系统的脚本
32位系统
cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86" | tar xzf -
64位系统
cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86_64" | tar xzf -
30元一年,打造自己的翻墙VPS

从此告别龟速的goagent,节省下来的时间会让你觉得很值。
为什么要自己搭梯子?
答:请看此试验 ----> 评测告诉你:那些免费代理悄悄做的龌蹉事儿
所以:免费的东西是最贵的!
更多性价比VPS请移步 老高推荐的VPS,希望大家在这里能够找到适合自己的VPS
使用shadowsocks轻松搭建翻墙环境教程
之前大家翻墙可能都会用到免费的goagent代理,但是他速度慢,链接也不稳定,看油管更是无望,更好的解决方案是shadowsocks。
shadowsocks是一个著名的轻量级socket代理,基于python编写。
如果你有国外的VPS,那么使用shadowsocks搭建一个翻{防屏蔽}墙服务器是一件很轻松的事情!
先看看shadowsocks覆盖的客户端覆盖了多少系统,连OpenWRT都支持!
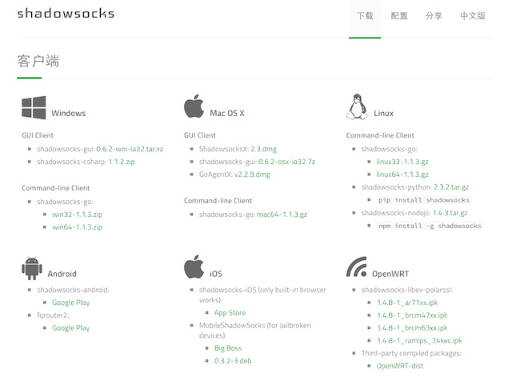
老高之前买的$4.99一年的VPS,128MB,用起来妥妥的!现在已经升级至$9.99,512MB内存,运行速度更快,翻{防屏蔽}墙速度更是没话说,如果你感兴趣,可以看看VPS购买攻略。
看完本文,你就能够轻松打造独享的翻{防屏蔽}墙环境!甚至能够将shadowsocks安装到你的路由器中,子网设备自动翻墙!再也不需要在网上购买shadowsocks的账号了,也不需要在忍受速度巨慢的免费shadowsocks账号了。
如果你的VPS是搬瓦工,那么恭喜你!你可以直接在后台一键安装shadowsocks,具体如何操作请参考使用搬瓦工(bandwagonhost)后台管理VPS&安全设置中如何一键安装shadowsocks一节,配置完毕后ss就会运行在后台,重启后也会自动运行。
友情提示:有些打包好的ss程序很难保证是否会记录你的服务器信息,所以一定要经常更新服务器端的密码或端口!或者,自己编译一个。。。。。
记一次goagent的设置
##下载
项目地址: https://github.com/goagent/goagent
APP配置
到https://appengine.google.com/新建一个或多个app,注意记录下app的ID!
一个appid每天只有1G的流量
上传服务器端脚本
解压至某文件夹,此处假设为d:\app\goagent318\,然后进去server,运行uploader.bat批处理
按提示输入信息即可,可能会很慢。
多个appid请用’|’隔开,即回车键上面那个
貌似现在一个帐号能创建25个app,每天25G流量,够用了吧?
只要在服务器上部署成功,以后就不用管server文件夹了 :-D ,除非你又要添加新的app才会用到!
此步骤只是把goagent的服务器端部署到你的在线APP上,等待你去调用他,所以下一步就是配置本地的文件,以实现对接。
部署成功的标志是看到这里的https://appengine.google.com/应用都在running即可!
本地配置
难点在这一步,废话比较多,我就粘贴一下官网的教程吧
编辑local\proxy.ini,把其中appid = goagent中的goagent 改成你之前申请的应用的appid (用windows的记事本也可以) 如果要使用多个appid,appid之间用|隔开,如:appid1|appid2|appid3,每个appid必须确认上传成功才能使用 格式 如下:
[gae]
appid = app-0|app-1|app-3|app-4
运行local下的goagent.exe,测试一下配置是否成功!推荐迅雷的代理测试
高级技巧
修改goagent端口
你可以修改端口以达到分流的作用,比如,使用默认8087端口上网用,再建一个使用8089端口的goagent,然后使用这个端口下载东西或者什么的,只要端口不冲突,你就可以建立多个代理,以达到分流的目的!
怎么修改呢?
先结束goagent进程,复制一份出来命名goagent318-d,原来的那个叫goagent318-w,d means download,w means web! 还是修改那个proxy.ini,找到[listen],应该在第一行,然后修改port = 8087为port = 8089,端口就改好了 讲appid按需分配给各个端口对应的程序,如我有十个app,给迅雷分5个,web分4个,再留一个备用!
在chrome中使用goagent
这个要用到SwitchySharp,怎么使用,自己百度吧!
goagent的GUI版本
这个挺不错的,方便小白使用,推荐下载绿色版!
围观地址:https://goagent.codeplex.com/
打造自己的网页代理
这个比较酷!不适用google,而是使用自己的网站做代理!只要你的主机在香港或者美国,就可以用PHP模拟成goagent的server端,然后就可以翻越GFW了
设置方法请参考
http://www.blogfeng.com/goagent-space-into-a-proxy-server-for-php.html
2015年1月12日更新:
- 更新项目地址
- fqrouter2已经停止更新
- 更好的翻墙方案 shadowsocks
PHP清除html格式
做采集的都知道,一般采集过来的内容难免会带有html标签,如果有太多的标签会影响之后的数据分析或提取,所以需要过滤掉!PHP已经为我们提供了很多清除html格式的方法了,下面就让老高介绍一下。
strip_tags
strip_tags($str) 去掉 HTML 及 PHP 的标记
语法: string strip_tags(string str);
传回值: 字串
函式种类: 资料处理
内容说明 :
解析:本函式可去掉字串中包含的任何 HTML 及 PHP 的标记字串。若是字串的 HTML 及 PHP 标签原来就有错,例如少了大于的符号,则也会传回错误。这个函数和 fgetss() 有着相同的功能
例子
echo strip_tags("Hello world!");
# Hello world!
htmlspecialchars
这个函数把html中的标签转换为html实体,博客的代码展示就必须使用这个函数,要不贴出来的代码就会被执行了。 预定义的字符是: & (和号) 成为 & ” (双引号) 成为 ” ‘ (单引号) 成为 ‘ < (小于) 成为 < > (大于) 成为 >
例子
$new = htmlspecialchars("Test", ENT_QUOTES);
echo $new;
# <a href='test'>Test</a>
# 如果需要展现
,那么浏览器解析HTML的时候会自动将他变为换行
# 但是通过htmlspecialchars就可以让< 变为 '
与htmlspecialchars功能相反的函数是htmlspecialchars_decode,他会把HTML实体转化为字符!
后补函数
PHP去除html、css样式、js格式的方法很多,但发现,它们基本都有一个弊端:空格往往清除不了 经过不断的研究,最终找到了一个理想的去除html包括空格css样式、js 的PHP函数。
$descclear = str_replace("\r","",$descclear);//过滤换行
$descclear = str_replace("\n","",$descclear);//过滤换行
$descclear = str_replace("\t","",$descclear);//过滤换行
$descclear = str_replace("\r\n","",$descclear);//过滤换行
$descclear = preg_replace("/\s+/", " ", $descclear);//过滤多余回车
$descclear = preg_replace("/<[ ]+/si","<",$descclear); //过滤<__("<"号后面带空格)
$descclear = preg_replace("/<\!--.*?-->/si","",$descclear); //过滤html注释
$descclear = preg_replace("/<(\!.*?)>/si","",$descclear); //过滤DOCTYPE
$descclear = preg_replace("/<(\/?html.*?)>/si","",$descclear); //过滤html标签
$descclear = preg_replace("/<(\/?head.*?)>/si","",$descclear); //过滤head标签
$descclear = preg_replace("/<(\/?meta.*?)>/si","",$descclear); //过滤meta标签
$descclear = preg_replace("/<(\/?body.*?)>/si","",$descclear); //过滤body标签
$descclear = preg_replace("/<(\/?link.*?)>/si","",$descclear); //过滤link标签
$descclear = preg_replace("/<(\/?form.*?)>/si","",$descclear); //过滤form标签
$descclear = preg_replace("/cookie/si","COOKIE",$descclear); //过滤COOKIE标签
$descclear = preg_replace("/<(applet.*?)>(.*?)<(\/applet.*?)>/si","",$descclear); //过滤applet标签
$descclear = preg_replace("/<(\/?applet.*?)>/si","",$descclear); //过滤applet标签
$descclear = preg_replace("/<(style.*?)>(.*?)<(\/style.*?)>/si","",$descclear); //过滤style标签
$descclear = preg_replace("/<(\/?style.*?)>/si","",$descclear); //过滤style标签
$descclear = preg_replace("/<(title.*?)>(.*?)<(\/title.*?)>/si","",$descclear); //过滤title标签
$descclear = preg_replace("/<(\/?title.*?)>/si","",$descclear); //过滤title标签
$descclear = preg_replace("/<(object.*?)>(.*?)<(\/object.*?)>/si","",$descclear); //过滤object标签
$descclear = preg_replace("/<(\/?objec.*?)>/si","",$descclear); //过滤object标签
$descclear = preg_replace("/<(noframes.*?)>(.*?)<(\/noframes.*?)>/si","",$descclear); //过滤noframes标签
$descclear = preg_replace("/<(\/?noframes.*?)>/si","",$descclear); //过滤noframes标签
$descclear = preg_replace("/<(i?frame.*?)>(.*?)<(\/i?frame.*?)>/si","",$descclear); //过滤frame标签
$descclear = preg_replace("/<(\/?i?frame.*?)>/si","",$descclear); //过滤frame标签
$descclear = preg_replace("/<(script.*?)>(.*?)<(\/script.*?)>/si","",$descclear); //过滤script标签
$descclear = preg_replace("/<(\/?script.*?)>/si","",$descclear); //过滤script标签
$descclear = preg_replace("/javascript/si","Javascript",$descclear); //过滤script标签
$descclear = preg_replace("/vbscript/si","Vbscript",$descclear); //过滤script标签
$descclear = preg_replace("/on([a-z]+)\s*=/si","On\\1=",$descclear); //过滤script标签
$descclear = preg_replace("/&#/si","&#",$descclear); //过滤script标签,如javAsCript:alert();
//使用正则替换
$pat = "/<(\/?)(script|i?frame|style|html|body|li|i|map|title|img|link|span|u|font|table|tr|b|marquee|td|strong|div|a|meta|\?|\%)([^>]*?)>/isU";
$descclear = preg_replace($pat,"",$descclear);
总结
采集这个东西说简单很简单,但说难真的很难。一旦遇到错误,就会让人很抓狂!
想要成为采集高手,你不仅需要了解从一个计算机发出的基于TCP的HTTP请求到最终得到请求的文件的整个过程,而且能够使用一系列的工具来协助你跟踪数据的去处,同时需要考虑你写出的采集任务的效率!
如果你需要采集twitter或者Facebook的数据,可以参考使用shadowsocks轻松搭建FQ环境