RWKV折腾记(基于RWKV-RUNNER)
最近chatgpt火的不要不要的,老高也靠着他节省了很多编码和调试的时间。
偶然的机会搜索到了RWKV这个开源的语言模型,刚好手头有一台配置还行的服务器,那就在服务器上部署一套试试。
升级驱动和cuda到最新(可选)
若计划使用NVIDIA显卡加速,建议将驱动程序升级至最新版,以获得最佳cuda支持。
请参考NVIDIA CUDA Toolkit Archive寻找合适版本。
升级cuda:以CentOS系统为例,根据NVIDIA的官方指导操作即可。通常情况下,无需重启系统:
这里可以使用nvida-smi查看驱动和显卡信息。
克隆项目
感谢josStorer的贡献,RWKV-Runner 工具提供了快捷的部署方式。
git clone https://github.com/josStorer/RWKV-Runner.git
安装依赖
RWKV-Runner 对 Python 3.10 的兼容性良好,准备开始之前,先编译安装。
cd /tmp
wget https://www.python.org/ftp/python/3.10.13/Python-3.10.13.tgz
tar zxf Python-3.10.13.tgz
cd Python-3.10.13
yum groupinstall "Development Tools" -y
yum install openssl-devel libffi-devel libffi-devel bzip2-devel -y
./configure
make
make install
# 先确认版本和路径
➜ ~ ls /usr/bin/python3* /usr/local/bin/python*
/usr/bin/python3 /usr/bin/python3.8-config /usr/local/bin/python3.10
/usr/bin/python3.6 /usr/bin/python3.8-x86_64-config /usr/local/bin/python3.10-config
/usr/bin/python3.6m /usr/bin/python3-config /usr/local/bin/python3-config
/usr/bin/python3.8 /usr/local/bin/python3
➜ ~ which python python3 pip pip3
/usr/bin/python
/usr/local/bin/python3
/usr/local/bin/pip
/usr/local/bin/pip3
# 设置软连接
ln -sf /usr/local/bin/python3.10 /usr/bin/python
ln -sf /usr/local/bin/python3.10 /usr/bin/python3
ln -sf /usr/local/bin/pip3.10 /usr/local/bin/pip
ln -sf /usr/local/bin/pip3.10 /usr/local/bin/pip3
ln -sf /usr/local/bin/python3.10-config /usr/bin/python-config
ln -sf /usr/local/bin/python3.10-config /usr/bin/python3-config
# 最后检查
➜ ~ python -V
Python 3.10.13
➜ ~ pip --version
pip 23.0.1 from /usr/local/lib/python3.10/site-packages/pip (python 3.10)
➜ ~
准备好了python3.10,我们开始安装依赖(也是一个很漫长的过程)
# 进入git仓库
cd RWKV-Runner
# 先升级一下pip
pip install --upgrade pip
pip install -r backend-python/requirements.txt
至此,python版本的RWKV-Runner已经可以跑了
➜ RWKV-Runner git:(master) ✗ python ./backend-python/main.py -h
usage: main.py [-h] [--port PORT] [--host HOST] [--webui] [--rwkv-beta] [--rwkv.cpp] [--webgpu]
options:
-h, --help show this help message and exit
server arguments:
--port PORT port to run the server on (default: 8000)
--host HOST host to run the server on (default: 127.0.0.1)
mode arguments:
--webui whether to enable WebUI (default: False)
--rwkv-beta whether to use rwkv-beta (default: False)
--rwkv.cpp whether to use rwkv.cpp (default: False)
--webgpu whether to use webgpu (default: False)
python ./backend-python/main.py --host 0.0.0.0 --port 8088
--- 0.7059581279754639 seconds ---
INFO: Started server process [2325754]
INFO: Waiting for application startup.
torch found: /usr/local/lib/python3.10/site-packages/torch/lib
torch set
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8088 (Press CTRL+C to quit)
模型下载与切换
选择合适的预训练模型,这里以 RWKV-5-World-3B 为例。下载模型后,通过接口切换至新模型:
# 创建模型目录并下载预训练模型
mkdir models
wget [模型下载链接] -O ./models/[模型文件名]
# 发送请求切换模型
curl -X POST [API URL] -H "Content-Type: application/json" -d '{"model":"[模型路径]","strategy":"cuda fp16","deploy":"true"}'
# 应返回 'success'
使用样例
在服务器部署完毕后,我们可以在本地安装聊天机器人软件(例如chatbot),配置AI服务器为刚刚搭建的模型服务器:
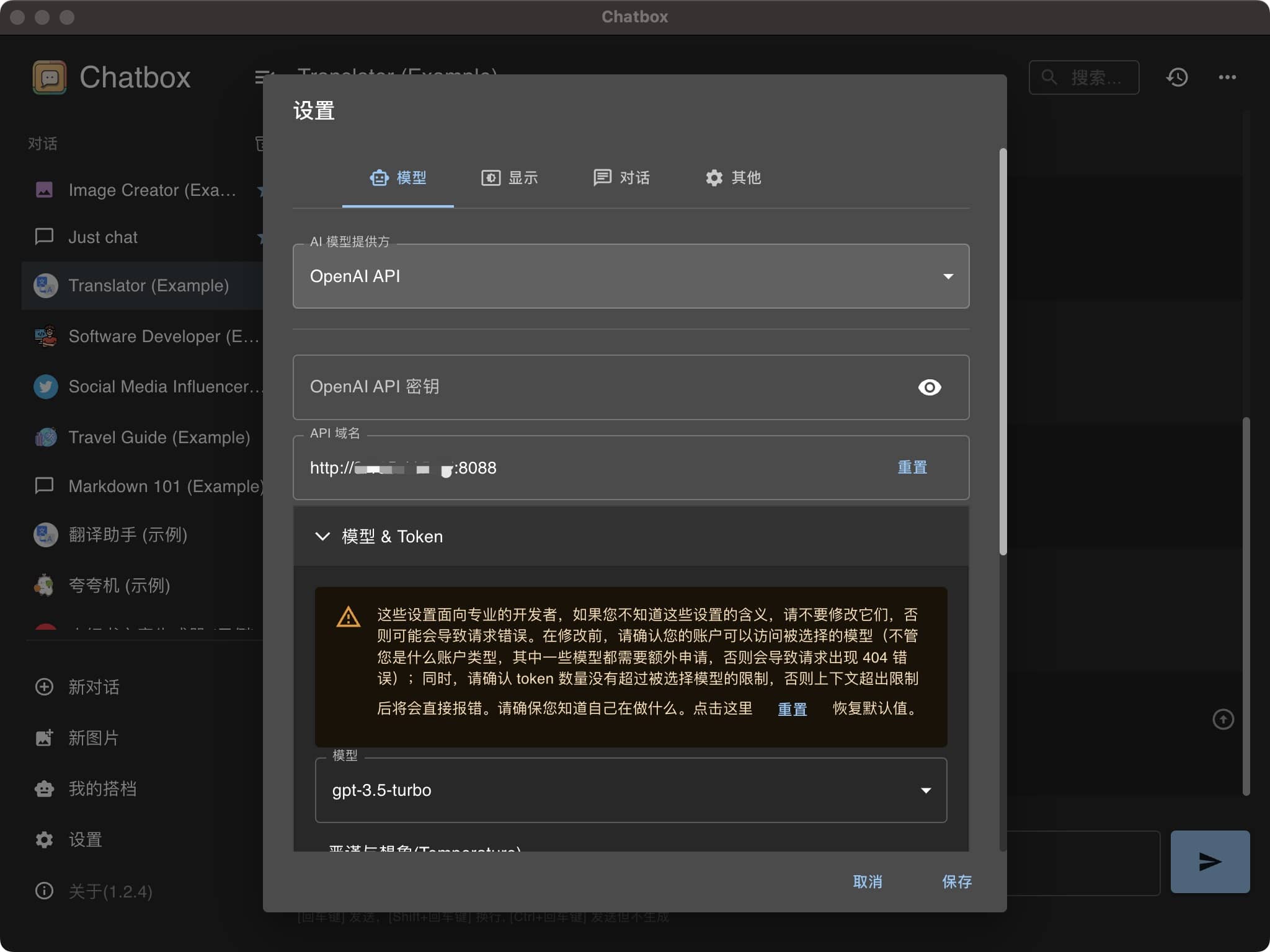
部署成功后,您可以体验独立的聊天机器人。
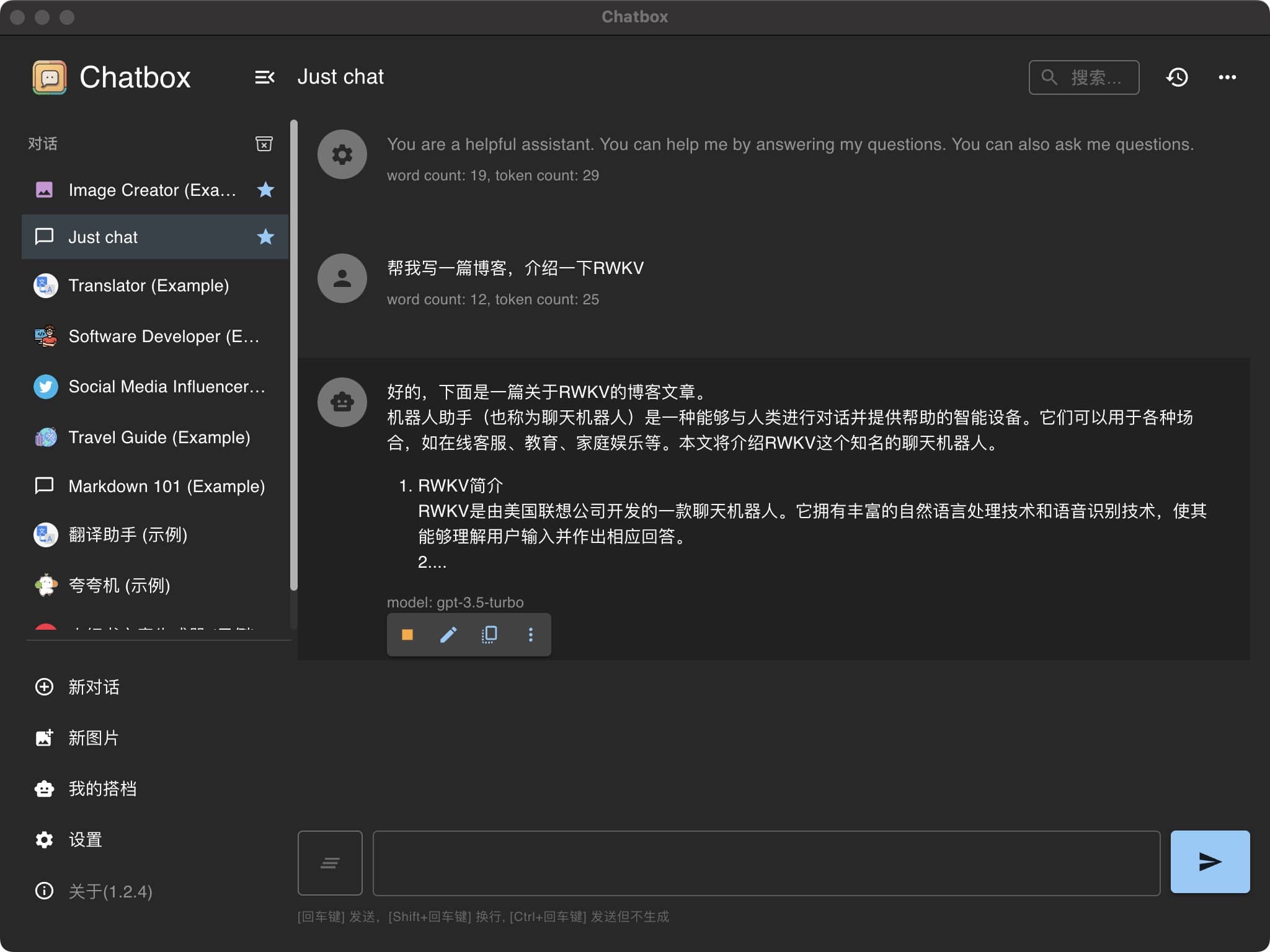
通过上述步骤,您不仅在服务器上成功部署了一个聊天机器人模型,而且通过简单的配置,实现了与本地应用的无缝对接。