puppeteer的使用教程1 - 基本用法
说到爬虫,就不得不接触一些反爬的技术了。其中,针对一些无法绕过或者无法正常阅读的JS代码,我们的最终法宝就是无头浏览器了!
无头浏览器其实就是为我们提供了一个环境,这个环境让我们可以使用一些指令,这些指令基本能够包含人们能够用到的所有操作,所以特别适合用来做一些自动化测试(界面,接口或者漏洞),或者爬虫。
在Puppeteer之前,还是有很多无头浏览器的,比如老牌的selenium,还有phantomJs,目前他们已经基本停止维护,所以我们今天的主角就是Puppeteer了!Puppeteer到底如何使用呢?使用的时候又有哪些坑呢?请听老高一一道来!
本篇是第一篇,主要让大家对Puppeteer有一个基本的概念!
官网和工具
由此可见,想要使用puppeteer,需要有使用node和npm的基础!
准备工作
nodejs的安装老高就不多说了,不过老高要啰嗦的是chromium的下载:
- 最好在安装puppeteer之前就下载解压好chromium,当然你也可以默认使用自带的浏览器。
- 执行安装脚本时如果程序没有找到chromium,会执行自动下载流程,这时如果检测到有
PUPPETEER_SKIP_CHROMIUM_DOWNLOAD这个环境变量,就不会下载了。 - 所以可以先执行
export PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true,再执行npm install命令。 - 安装完成后,在脚本中启动chrome的参数中加入
executablePath,并指向对应路径即可。 - win下路径要填写到exe,linux下是chrome,而MacOS下则是
Chromium.app/Contents/MacOS/Chromium,不要填错了! - 为了保证测试环境和生产环境的版本一致性,一定要记录Chromium的版本号。
第一个脚本
首先找一个干净的文件夹,比如 try_puppeteer,然后找到chrome的安装路径为/Users/xxx/code/Chromium.app/Contents/MacOS/Chromium,很明显,老高的系统为MacOS。最后将下面的代码保存为1.js,如果是安装程序自动下载的浏览器,请把args置为{}即可!
const puppeteer = require('puppeteer');
args = {
executablePath: '/Users/xxx/code/Chromium.app/Contents/MacOS/Chromium',
};
(async () => {
const browser = await puppeteer.launch(args);
const page = await browser.newPage();
await page.goto('https://www.mi.cn');
await page.screenshot({ path: 'mi.png' });
await browser.close();
})();
执行完毕后,文件夹中应该多了一个叫mi.png的文件,其内容为小米的官网,对吗?
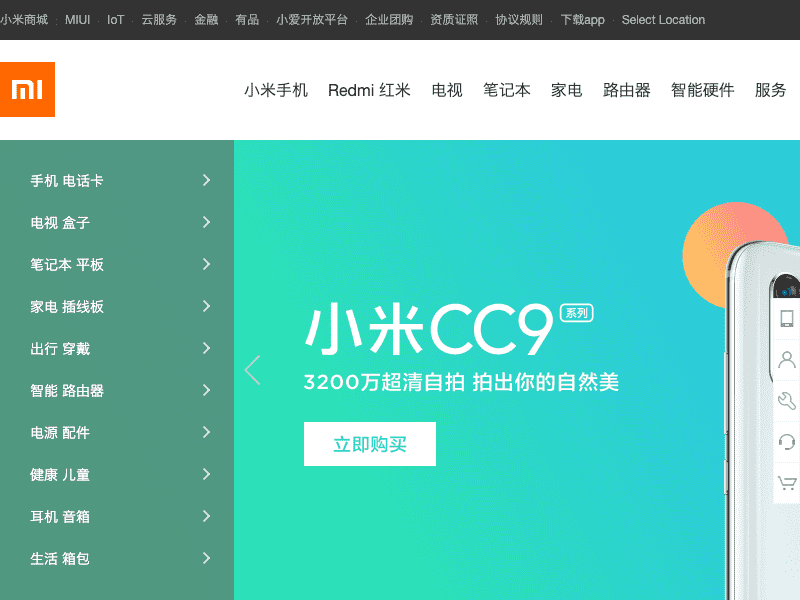
至此,你的第一个puppeteer程序已经搞定!如果没有,请在下方留言,告诉老高你遇到的问题,老高十分乐意为你解答!
谢谢分享
没有讲清楚,如果应用的好处走向
污泥螺杆泵
污泥螺杆泵