模拟登录联通10010.com查询宽带余额
家里的宽带是包年按天扣费,时间长了就忘了改什么时候续费了。
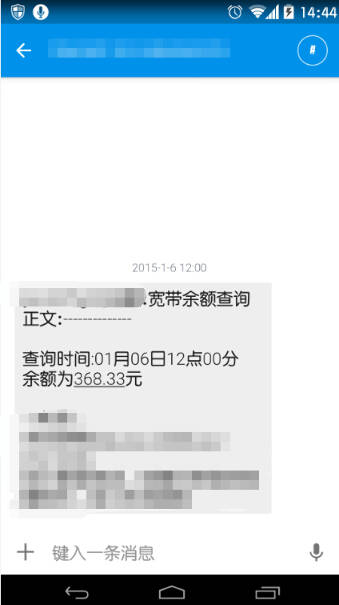
抽时间写了个模拟登录10010.com的脚本,自动查询余额。
每天中午12点查一次,省得下次又欠费了。
模拟登录的过程很简单,获取查询的cookie需要两步请求,拿到cookie后可以随意查询。
有TX想看源码么?
已贴源码
#!/usr/bin/env python
# encoding: utf-8
"""
@version: 0.2
@author: phpergao
@license: Apache Licence
@contact: [email protected]
@site: http://www.phpgao.com
@software: PyCharm
@file: 10010.py
@time: 15-1-3 下午6:06
一键查询联通宽带余额
"""
import urllib2
import cookielib
import json
class Crawl():
def __init__(self, username, passwd, debug=False):
(self.username, self.passwd) = (username, passwd)
self.cookie = cookielib.CookieJar()
cookieHandler = urllib2.HTTPCookieProcessor(self.cookie)
self.is_debug = debug
if self.is_debug:
httpHandler = urllib2.HTTPHandler(debuglevel=1)
httpsHandler = urllib2.HTTPSHandler(debuglevel=1)
opener = urllib2.build_opener(cookieHandler, httpHandler, httpsHandler)
else:
opener = urllib2.build_opener(cookieHandler)
urllib2.install_opener(opener)
self.last_url = ''
def get_html(self, url, postdata=''):
print "Requesting for %s" % url
if postdata != '':
req = urllib2.Request(url, postdata)
else:
req = urllib2.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Ubuntu; X11; Linux i686; rv:8.0) Gecko/20100101 Firefox/8.0')
req.add_header('Content-Type', 'application/x-www-form-urlencoded')
req.add_header('Cache-Control', 'no-cache')
req.add_header('Accept', '*/*')
req.add_header('Connection', 'Keep-Alive')
try:
resp = urllib2.urlopen(req)
except Exception as e:
print e
self.last_url = url
if self.is_debug:
print "method: %s" % req.get_method()
crawl.tell_cookie()
return resp
def tell_cookie(self):
for item in self.cookie:
print "cookie name : %s ---- value: %s" % (item.name, item.value)
def get_balance(self):
# 首页
url_home = "http://www.10010.com/"
# 登录主页
url_login = "https://uac.10010.com/portal/mallLogin.jsp?redirectURL=http://www.10010.com"
# 登录框架页
url_frame = "https://uac.10010.com/portal/homeLogin"
# 登录地址
# 这里需要观察一下chrome的发送信息,需要自己改的有areaCode和arrcity
# 就是登录时候选择的信息
# 说是post,其实只是明文GET 囧
# 无力吐槽
url_post = "https://uac.10010.com/portal/Service/MallLogin?callback=jQuery172006519943638704717_" \
"1420279331097&redirectURL=http%3A%2F%2Fwww.10010.com&userName=" + str(self.username) + "&password=" \
+ str(self.passwd) + "&pwdType=01&productType=04&redirectType=01&rememberMe=1&areaCode=841" \
"&arrcity=%E8%A5%BF%E5%AE%89"
# 点击查询按钮链接
cookie1 = "http://iservice.10010.com/ehallService/static/login/r?menuid=000100010013"
# 点击后获取到key为e3的cookie,参数可能会变
cookie2 = "http://iservice.10010.com/e3/static/check/checklogin/?_=1420301171070"
# 查询余额页面
url_balance = "http://iservice.10010.com/e3/query/account_balance.html"
# 查询余额接口
url_last = "http://iservice.10010.com/e3/static/query/accountBalance/search?"
# self.get_html(url_home)
# self.get_html(url_login)
self.get_html(url_frame)
self.get_html(url_post)
self.get_html(url_home)
self.get_html(cookie1)
# a=1意思是将请求方法变为POST
self.get_html(cookie2, "a=1")
self.get_html(url_balance)
return self.get_html(url_last, "a=1")
if __name__ == '__main__':
crawl = Crawl(xxxxx, xxxxx)
info = crawl.get_balance()
data = json.load(info)
print data['realtimebalance']
数据拿到了剩下的问题就是如果发送到手机了,老高前几天写了个飞信发送短信脚本,中国移动的用户有福了。
你好,请问fetion接口是不是不管用了。总是提示登录错误,而且3G飞信地址也改成了/im5/
刚才看了一下,这个登陆接口报错 您当前使用非cmwap方式接入 应该是限制IP了
手机上登陆直接就识别用户了,电脑端f.10086.cn/im5/登陆需要动态获取验证码,如果能解决麻烦push一下,学习学习。
验证码也不管用吧,只能短信验证码,验证码界面我登陆了,到http://f.10086.cn/im5/界面还是未登陆状态。==
哎,现在要么需要短信验证要么需要验证码。。。目前mac的客户端不需要验证码,改天抓包看看
原来的登陆界面是这个http://f.10086.cn/huc/user/space/login.do?m=submit&fr=space,飞信好友发送等页面都在http://f.10086.cn/im/下面,现在所有操作好像都移到了http://f.10086.cn/im5/下面,包括登录改成了获取动态短信验证码。之前的登陆界面这个http://f.10086.cn/huc/user/space/login.do?m=submit&fr=space与飞信好友发送等页面脱离了关系
能说具体一点吗,我目前就找到这个页面 http://f.10086.cn/huc/user/xiaoyuan/login.do?m=tologin&backurl=http%3A%2F%2Ff.10086.cn%2Fxiaoyuan%2Ftryaward%2Ftryaward.do
#!/usr/bin/env python # encoding: utf-8 """ """ import urllib2 import cookielib import json class Crawl(): def __init__(self, username, passwd, debug=True): (self.username, self.passwd) = (username, passwd) self.cookie = cookielib.CookieJar() cookieHandler = urllib2.HTTPCookieProcessor(self.cookie) self.is_debug = debug if self.is_debug: httpHandler = urllib2.HTTPHandler(debuglevel=1) httpsHandler = urllib2.HTTPSHandler(debuglevel=1) opener = urllib2.build_opener(cookieHandler, httpHandler, httpsHandler) else: opener = urllib2.build_opener(cookieHandler) urllib2.install_opener(opener) self.last_url = '' def get_html(self, url, postdata=''): print "Requesting for %s" % url if postdata != '': req = urllib2.Request(url, postdata) else: req = urllib2.Request(url) req.add_header('User-Agent', 'Mozilla/5.0 (Ubuntu; X11; Linux i686; rv:8.0) Gecko/20100101 Firefox/8.0') req.add_header('Content-Type', 'application/x-www-form-urlencoded') req.add_header('Cache-Control', 'no-cache') req.add_header('Accept', '*/*') req.add_header('Connection', 'Keep-Alive') try: resp = urllib2.urlopen(req) except Exception as e: print e self.last_url = url if self.is_debug: print "method: %s" % req.get_method() crawl.tell_cookie() print self.cookie return resp def tell_cookie(self): for item in self.cookie: print "cookie name : %s ---- value: %s" % (item.name, item.value) def get_balance(self): # 首页 url_home = "http://www.10010.com/" # 登录主页 url_login = "https://uac.10010.com/portal/mallLogin.jsp?redirectURL=http://www.10010.com" # 登录框架页 url_frame = "https://uac.10010.com/portal/homeLogin" # 登录地址 # 这里需要观察一下chrome的发送信息,需要自己改的有areaCode和arrcity # 就是登录时候选择的信息 # 说是post,其实只是明文GET 囧 # 无力吐槽 # url_post = "https://uac.10010.com/portal/Service/MallLogin?callback=jQuery172006519943638704717_" \ # "1420279331097&redirectURL=http%3A%2F%2Fwww.10010.com&userName=" + str(self.username) + "&password=" \ # + str(self.passwd) + "&pwdType=01&productType=04&redirectType=01&rememberMe=1&areaCode=841" \ # "&arrcity=%E8%A5%BF%E5%AE%89" url_post = "https://uac.10010.com/portal/Service/MallLogin?callback=jQuery17208090539523400366_1447320746303&redirectURL=http%3A%2F%2Fwww.10010.com&userName=我的手机号&password=我的密码&pwdType=01&productType=01&redirectType=01&rememberMe=1&_=1447320759882" self.get_html(url_home) self.get_html(url_login) self.get_html(url_frame) return self.get_html(url_post) # self.get_html(url_home) # self.get_html(cookie1) # # a=1意思是将请求方法变为POST # self.get_html(cookie2, "a=1") # self.get_html(url_balance) # return self.get_html(url_last, "a=1") if __name__ == '__main__': crawl = Crawl('我的手机号', '我的密码') info = crawl.get_balance() data = info.read() print data crawl.get_html('http://www.10010.com').read() crawl.get_html('http://www.10010.com/1111.html').read() fp = open('d:\\test.html', 'wb') fp.write(crawl.get_html('http://www.10010.com/?refer=1').read()) fp.close() 大神您好 我照着您的代码想模拟登陆 发现返回的主页是未登陆的状态 可以帮我看看是怎么回事吗? 我觉得没问题就是登不上去 是不是联通这边做了修改 ?
源码能否贴出来看看
已经贴出来了